
说明:这里记录了一些应用层开发的基础知识,都是科普的形式,若想深入了解,请自行学习
gcc
编译,将.c源文件转化为.o目标文件
gcc -c main.c -o main.o
-c:gcc只执行到汇编阶段,生成目标文件,而不进行最后的链接
-o:指定输出的名称
底层发生的四个步骤
- 预处理:gcc -E main.c -o main.i —->处理宏定义、包含头文件,生成main.i
- 编译:gcc -S main.i -o main.s ——> 将代码翻译成汇编语言,并进行语法检查
- 汇编:gcc -c main.s -o main.o ——-> 将汇编代码转化为二进制机器码
- 链接:静态链接 -> gcc -static main.o -o main;动态链接 -> gcc main.o -o main ——->将多个.o和库文件打包成可执行程序
文件I/O
C标准I/O库函数
fopen:打开文件
// const char *__restrict __filename:字符串表示要打开的文件名称
// const char *__restrict __modes:访问模式
// (1) r:只读模式 如果没有文件报错
// (2) w:只写模式 如果文件存在清空文件 如果不存在创建新文件
// (3) a:只追加写模式 如果文件存在末尾追加写 如果不存在创建新文件
// (4) r+:读写模式 文件必须存在 写入是从头一个一个覆盖
// (5) w+:读写模式 如果文件存在清空文件 如果不存在创建新文件
// return: FILE * 结构体指针 表示一个文件
// 报错返回NULL
// ILE *fopen (const char *__restrict __filename,
// const char *__restrict __modes)
fclose:关闭文件
/**FILE *__stream:需要关闭的文件
* return: 成功返回0 失败返回EOF(负数),通常关闭文件会直接报错
* int fclose (FILE *__stream);
*/
fputc:写入字节
/**
* int __c:ASCII码对应的char
* FILE *__stream:打开的一个文件
* return:成功就返回char 失败返回EOF
* int fputc (int __c, FILE *__stream);
*/
fputs:写入字符串
/**
* const char *__restrict __s:需要写入的字符串
* FILE *__restrict __stream:需要写入的文件
* return:成功返回非负整数(0,1) 失败返回EOF
* int fputs (const char *__restrict __s, FILE *__restrict __stream);
*/
fprintf:格式化写入
/**
* FILE *__restrict __stream:打开的文件
* onst char *__restrict __fmt:带格式化的长字符串
* ... 可变参数:填入格式化的长字符串
* return:成功返回写入的字符的个数 不包含换行符 失败方会EOF
* fprintf (FILE *__restrict __stream, const char *__restrict __fmt, ...)
*/
fgetc:读取字节
/**
* FILE *__stream:打开的文件
* return:读取到的一个字节 如果出错或者到文件的末尾EOF
* int fgetc (FILE *__stream);
*/
fgets:读取字符串
// 读取文件内容
/**
* char *__restrict __s:接收读取到的字符串
* int __n:接收数据的长度
* ILE *__restrict __stream:打开要读取的文件
* return:成功返回字符串 失败返回NULL 可以直接使用while
* fgets (char *__restrict __s, int __n, FILE *__restrict __stream)
*/
fscanf:格式化读取
/**
* FILE *__restrict __stream:要打开的文件名
* const char *__restrict __format:带有格式化的字符串(固定格式接收)
* ...可变参数:填写格式化的字符串(接受数据提前声明的变量)
* return:成功匹配到的参数的个数 如果匹配失败返回0,报错或者文件结束EOF
* int fscanf (FILE *__restrict __stream,
const char *__restrict __format, ...)
*/
系统调用
系统调用是操作系统内核提供给应用程序,使其可以间接访问硬件资源的接口。
open
open()系统调用用于打开一个标准的文件描述符
/**
* char *__path:打开文件的路径
* int __oflag:打开文件的模式
* (1) O_RDONLY 只读模式
* (2) O_WRONLY 只写模式
* (3) O_RDWR 读写模式
* (4) O_CREAT 如果不存在创建文件
* (5) O_APPEND 追加写模式
* (6) O_TRUNC 截断文件长度为0
* ...可变参数:O_CREAT 只有在读写模式时才要加,创建文件的权限 0
* return:文件描述符 如果打开文件失败 返回-1 同时设置全局变量errno表示对应的错误
* int open (const char *__path, int __oflag, ...)
*/
read
/**
* int __fd:文件描述符
* void *__buf:存放数据
* size_t __nbytes:读取数据的长度
* return:ssize_t -> long int : 读取到的数据的字节长度 成功大于0 失败-1
* ssize_t read (int __fd, void *__buf, size_t __nbytes)
*/
write
/**
* int __fd:文件描述符
* const void *__buf:要写出的数据
* size_t __n:写出的长度
* return:成功返回写出数据的长度 失败返回-1
* ssize_t write (int __fd, const void *__buf, size_t __n)
*/
close
/**
* 关闭打开的文件描述符
* int __fd:关闭的文件
* 成功返回0,失败返回-1
* int close (int __fd);
*/
文件描述符
在linux系统中,当我们打开或创建一个文件(或套接字)时,操作系统会提供一个文件描述符(File Descriptor, FD),这是一个非负整数,我们可以通过它来进行读写等操作。
然而,文件描述符本身只是操作系统为应用程序操作底层资源(如文件、套接字等)所提供的一个引用或”句柄“
在Linux中,文件描述符0、1、2是有特殊含义的。
- 0是标准输入(stdin)的文件描述符
- 1是标准输出(stdout)的文件描述符
- 2是标准错误(stderr)的文件描述符
文件描述符关联的数据结构
1. struct file
每个文件描述符都关联到内核一个struct file类型的结构体数据,结构体定义位于Linux系统的/usr/src/linux-hwe-6.5-headers-6.5.0-27/include/linux/fs.h文件中。
该结构体的部分关键字段如下:
struct file{
...
atomic_long_t f_count; // 引用计数,管理文件对象的生命周期
struct mutex f_pos_lock; // 保护文件位置的互斥锁
loff_t f_pos; // 当前文件位置 (读写位置)
...
struct path f_path; // 记录文件路劲
struct inode *f_inode; // 指向与文件相关联的inode对象的指针,该对象用于维护文件元数据,如文件类型、访问权限等。
const struct file_operations *f_op; // 指向文件操作函数表的指针,定义了文件支持的操作,如读、写、锁定等
...
void *private_data; // 存储特定驱动或模块的私有数据
...
} __randomize_layout
__attribute__((aligned(4)));
这个数据结构记录了与文件相关的所有信息,其中比较关键的是f_path记录了文件的路径信息,f_inode记录了文件的元数据。
2. struct path
结构体定义位于Linux系统的/usr/src/linux-hws-6.5-headers-6.5.0-27/include/linux/path.h文件中
struct path {
struct vfsmount *mnt;
struct dentry *dentry;
} __randomize_layout;
该结构体只有两个属性
- struct vfsmount: 是虚拟文件系统挂载点的表示,存储有关挂在文件系统的信息。
- struct dentry:目录项结构体,代表了文件系统中的一个目录项,目录项是文件系统中的一个实体,通常对应一个文件或目录的名字。通过这个类型的属性,可以定位文件位置。
3. struct inode
结构体定义位于Linux系统的/usr/src/linux-hws-6.5-headers-6.5.0-27/include/linux/fs.h文件中
struct inode {
umode_t i_mode; // 文件类型和权限。这个字段指定了文件是普通文件、目录、字符设备、块设备等,以及它的访问权限(读、写、执行)
unsigned short i_opflags;
kuid_t i_uid; // 文件的用户ID,决定了文件的拥有者
kgid_t i_gid; // 文件的组ID,决定了文件的拥有着组
unsigned int i_falgs;
...
unsigned long i_ino; // inode编号,是文件系统中文件的唯一标识
...
loff_t i_sizel; // 文件大小
} __randomize_layout;
文件描述符表关联的数据结构
1. struct file_struct
打开的文件表数据结构:用来维护一个进程(上下文介绍)中所有打开我呢见信息的
结构体定义位于Linux系统的/usr/src/linux-hws-6.5-headers-6.5.0-27/include/linux/fdtable.h文件中
struct file_struct {
...
struct fdtable _-rcu *fdt; // 指向当前使用的文件描述符表(fdtable)
...
unsigned int next_fg; // 存储下一个可用的最小文件描述符编号
...
struct file __rcu *fd_array[NR_OPEN_DEFAULT]; // struct file 指针的数组,大小固定,用于快速访问
}
fdt维护了文件描述符表,其中记录了所有打开的文件描述符和struct file的对应关系。
2. struct fdtable
打开文件描述符表:打开文件描述符表底层的数据结构
结构体定义位于Linux系统的/usr/src/linux-hws-6.5-headers-6.5.0-27/include/linux/fdtable.h文件中
struct fdtable {
unsigned int max_fds; // 文件描述符数组的容量,即可用的最大文件描述符
struct file __rcu **fd; // 指向struct file 指针数组的指针
unsigned long *close_on_exec;
unsigned long *open_fds;
unsigned long *full_fds_bits;
struct rcu_head rcu;
}
3. fd_array 和 fd
fd_array是一个定长数组,用于存储进程中最常见的struct file
fd是一个指针,可以指向任何大小的数组,其大小由max_fds字段控制,它可以根据需要动态扩展,以容纳更多的文件描述符
当打开文件描述符的数量不多于 NR_OPEN_DEFAULT时,fd指向的通常就是fd_array,当文件描述符的数量超过NR_OPEN_DEFAULT时,会发生动态扩容,会将fd_array的内容复制到扩容后的指针数组,fd指向扩容后的指针数组,这一过程时内核控制的。
文件描述符是一个非负整数,其值实际上就是其关联的struct file 在 fd 指向的数组或fd_array 中的下标。
4. 图解
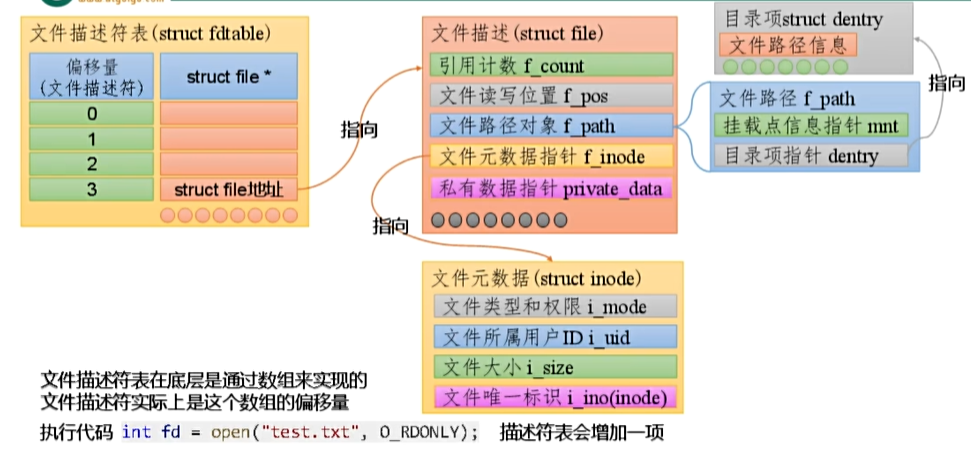
5. 小结
当我们执行open()等系统调用时,内核会创建一个新的struct file, 这个数据结构记录了文件的元数据(文件类型、权限等)、文件路径、支持的操作等,然后分配文件描述符,将struct file维护在文件描述符表中,最后将文件描述符返回给应用程序。我们可以通过后者对文件执行它所支持的各种函数操作,而这些函数的函数指针都维护子啊struct file_operations数据结构中。文件描述符实质上是底层数据结构struct file的一个引用或者句柄,它为用户提供了操作底层文件的入口。
进程处理
Liunx进程简介
进程(Process)是正在运行的程序,是操作系统进行资源分配和调度的基本单位。程序是存储在硬盘或内存的一段二进制序列,是静态的,而进程是动态的。进程包括代码、数据以及分配给它的其他系统资源(如文件描述符、网络连接等)。
1. system函数生成子进程
system函数是标准库中执行shell指令的函数。
/**
* const char *__command:使用Linux命令直接创建一个子进程
* return:成功返回0 失败返回失败编号
* int system (const char *__command) __wur;
*/
ps -ef查看所有进程
2. 进程处理相关函数调用
system函数用到的系统调用为fork、execve和waitpid。
int main(void);无参main函数
int main(int argc, char *argv[]);有参形式
- argc:传递给程序的命令行参数的数量
- argv:指向字符串数组的指针,存储了命令行参数
- argv[0]通常是程序的名称
- argv[1]到argv[argc-1]是实际的命令行参数
2.1. fork
pid:procee id:进程id
fork():复制一个子进程,返回子进程进程号
fork之前父进程单独运行
从fork之后,所有的代码都是在父子进程中各自执行一次的,通过pid进行区分
getpid():获取当前的进程号
getppid():获取父进程的进程号
// 使用fork创建子进程
/**
* 不需要传参
* return:int 进程号
* (1): -1 出错
* (2): 父进程中表示子进程的PID
* (3): 子进程中显示为0
* __pid_t fork (void)
*/
2.2 execve
可以在同一个进程中跳转执行另外一个程序,可执行程序
// 执行跳转
/**
* const char *__path: 执行程序的路径
* char *const __argv[]: 传入的参数 -> 对应执行程序main方法的第二个参数
* (1): 第一个参数固定是程序的名称 -> 执行程序的路径
* (2): 执行程序需要传入的参数
* (3): 最后一个参数一定是NULL
* char *const __envp[]: 传递的环境变量
* (1): 环境变量参数: key=value
* (2): 最后一个参数一定是NULL
* return: 成功根本没办法返回 下面的代码也没有意义
* 失败返回-1
* 跳转前后只有进程号保留下来 别的都删除了
* int execve (const char *__path, char *const __argv[],char *const __envp[])
*/
2.3 waitpid
Linux中父进程除了可以启动子进程,还要负责回收子进程的状态,如果子进程结束后父进程没有正常回收,那么子进程就会编程一个僵尸进程–即程序执行完成,但是进程没有完全结束,其内核中PCB结构体没有释放。
/**
* pid: 等待的模式
* (1) 小于-1 例如 -1 * pgid,则等待进程组ID等于pgid的所有进程终止
* (2) 等于-1 会等待任何子进程终止,并返回最先终止的那个子进程的进程ID -> 儿孙都算
* (3) 等于0 等待同一进程组中任何子进程种植(但不包括组领导进程) -> 只算儿子
* (4) 大于0 仅等待制定进程ID的子进程种植
* wstatus: 整数指针,子进程返回的状态码会保存到该int
* options: 选项的值是以下常量之一或多个的按位或(OR)运算的结果,二进制对应选项,可多选;
* (1) WNOHANG 如果没有子进程终止,也立即返回;用于查看子进程状态而非等待
* (2) WUNTRACED 收到子进程处于收到信号停止的状态,也返回
* (3) WCONTINUED 如果通过发送 SIGCONT 信号恢复了一个已停止的子进程,则也返回
* return: (1) 成功等到子进程停止 返回pid
* (2) 没等到并且没有设置WNOHANG 一直等
* (3) 没等到设置WNOHANG 返回0
* (4) 出错返回-1
* __pid_t __pid: 传入的pid号
* __pid_t waitpid (__pid_t __pid, int *__stat_loc, int __options)
*/
3. 进程树
Linux的进程是通过父子关系组织起来的,所有进程之间的父子关系共同构成了进程树(Process Tree)
。进程树中每个节点都是其上级节点的子进程,同时又是子节点的父进程。一个进程的父进程只能有一个,而一个进程的子进程可以不止一个。
4. 孤儿进程
孤儿进程是指父进程已经结束或终止,而它仍在运行的进程。
当父进程结束之前没有等待子进程结束,且父进程先于子进程结束时,那么子进程就会变成孤儿进程
进程间通信
进程之间的内存是隔离的,如果多个进程之间需要进行信息交换,常用的方法有一下几种:
- Unix Doman Socket IPC
- 管道(有名管道、无名管道)
- 共享内存
- 消息队列
- 信号量
1. 匿名管道(Pipe)
1. perror() 和 errno
当系统调用或库函数发生错误时,通常会通过设置全局变量 errno 来指示错误的具体原因。errno 是在C语言(及其在Unix、Linux系统下的应用)中用来存储错误号的一个全局变量。每当系统调用或某些库函数遇到错误,无法正常完成操作时,他会将一个错误代码存储到erron中。这个错误代码提供了失败的具体原因,程序可以通过检查errno的值来确定发生了什么错误,并据此进行相应的错误处理。
errno定义在头文件< errno.h >中,引入该文件即可调用全局变量errno。
perror函数用于将errno当前值对应的错误描述以人类可读的形式输出到标准错误输出(stderr)。
参数s:指向一个字符串的指针,如果s不是空指针且指向的不是\0字符,则perror会在s后添加一个冒号和空格作为前缀,输出错误信息,否则不输出前缀,直接输出错误信息。
2. pipe
匿名管道是位于内核的一块缓冲区,用于进程间通信。创建匿名管道的系统调用为pipe。
在内核空间创建管道,用于父子进程或者其他相关联的进程之间通过管道进行双向的数据传输。
pipeff: 用于返回指向管道两端的两个文件描述符。pipefd[0]指向管道的读端。pipefd[1]指向管道的写端。
return: 成功 0
不成功 -1 并且pipefd不会改变
int pipe(int pipefd[2]);
3. 宏定义
- EXIT_FAILURE:表示以失败状态退出进程
- EXIT_SUCCESS:表示以成功状态退出进程
- STDOUT_FILENO:表示标准输出
使用管道的限制:
- 两个进程通过一个管道只能实现单向通信,比如上面的例子,父进程写子进程读,如果有时候也需要子进程写父进程读,就必须另开一个管道。
- 管道的读写端通过打开的文件藐视符来传递,因此要通信的两个进程必须从他们的公共祖先那里继承管道文件描述符。上面的例子是父进程把文件描述符传给子进程之后,父子进程之间通信,也可以父进程fork两次,把文件描述符传给两个子进程,然后两子进程之间通信,总之需要通过fork传递文件描述符使两个进程都能访问统一管道,他们才能通信。
管道返回的文件描述符
管道返回的两个文件描述符反别表示读写,各自指向一个struct file结构体,然而,他们并不对应真正的文件。
当我们开启管道时,父进程会创建两个struct file 结构体用于管道的读写操作,并为二者各自分配一个文件描述符,他们的private_data属性指向同一个struct pipe_inode_info的结构体,由后者管理对于管道缓冲区的读写,通过fork()创建一个子进程,后者会继承文件描述符,指向相同的struct file结构体。
2. 有名管道
pipe是匿名管道,只能在有父子关系的进程间使用,某些场景下并不能满足需求。与匿名管道相对的是有名管道,在Linux中称为FIFO,即First In First Out, 先进先出队列。
FIFO和Pipe一样,提供了双向进程间通信渠道。但是要注意的是,无论是有名管道还是匿名管道,同一条管道只应用于单向通信,否则可能出现通信混乱。
有名管道可以用于任何进程之间的通信。
mkfifo
创建有名管道,内核为每个被进程打开的FIFO专用文件维护一个管道对象。当进程通过FIFO交换数据时,内核会在内部传递所有数据,不会将其写入文件系统。因此,/tem/myfifo文件大小始终为0。需要注意的是,文件详细信息最开头的字母p表示这个是一个有名管道文件。
3. 共享内存
1. shm_open() /shm_unlink()
shm_open 可以开启一块内存共享对象,我们可以像使用一般文件描述符一般使用这块内存对象。
/**
* const char *name: 这是共享内存对象的名称,直接写一个文件名称,本身会保存在/dev/shm。
* 名称必须是唯一的,以便不同进程可以定位同一个共享内存段。
* 命名规则: 必须是以正斜杠/开头,以\0结尾的字符串,中间可以包含若干字符串,但是不能有正斜杠
* int oflag: 打开模式 二进制可拼接
* (1) O_CREAT: 如果不存在则创建新的共享内存对象
* (2) O_EXCL: 当与 O_CREAT 一起使用时,如果共享内存对象已经存在,则返回错误
* (3) O_RDONLY: 以只读方式打开
* (4) O_RFWR: 以读写方式打开
* (5) O_TRUNC: 用于截断现有对象至0长度(只有在打开模式中包含 0_RDWR 时才有效)
* mode_t mode: 当创建新共享内存对象时使用的权限位,类似与文件的权限模式,一般0644即可
* return: 成功执行,它将返回一个新的描述符;发生错误,返回值-1
* int shm_open(const char *name, int oflag, mode_t mode);
*/
/**
* 删除一个先前由 shm_open() 创建的命名共享内存对象,尽管这个函数被称为"unlink",但它并没有真正删除共享
* 内存段本身,而是移除了与共享内存对象关联的名称,使得通过该名称无法再打开共享内存。当所有已打开该共享内存
* 段的进程关闭它们的描述符后,系统彩绘真正释放共享内存资源。
* char *name: 要删除的共享内存对象名称
* return: 成功返回0 失败返回-1
* int shm_unlink(const char *name)
*/
2. truncate() / ftruncate()
truncate 和 ftruncate都可以将文件缩放到指定大小,二者的行为类似:如果文件被缩小,截断部分的数据丢失,如果文件空间被放大,扩展的部分均为\0字符。缩放前后文件的偏移量不会更改,缩放成功返回0,失败返回-1.
不同的是,前者需要指定路径,而后者需要提供文件描述符;ftruncate 缩放的文件描述符可以是通过shm_open() 开启的内存对象,而truncate 缩放的文件必须是文件系统已存在文件,若文件不存在或没有权限会失败。
3. mmap()
mmap系统调用可以将一组设备或者文件映射到内存地址,我们在内存中寻址就相当于在读取这个文件指定地址的数据。父进程在创建一个内存共享对象将其映射到内存区后,子进程可以正常读写改内存区,并且父进程也能看到更改。使用man 2mmap查看该系统调用声明
4. 临时文件系统
Linux的零食文件系统(tmpfs)是一种基于内存的文件系统,它将数据存储在RAM或者在需要时部分使用交换空间(swap)。tmpfs访问速度快,但因为存储在内存,重启后数据清空,通常用于存储一些临时文件
可以通过df -h 查看当前操作系统已挂载的文件系统.
内存共享对象在临时文件系统中的表示位于/dev/shm目录下
/**
* sprintf: 将格式化的数据写入字符串
* char *str: 这是指向一个字符数组的指针,用于存储生成的字符串
* const char *format: 格式化控制字符串(如%d,%s,%f等)
* ...: 要转换的变量。
* int sprintf(char *str, const char *format, ...);
*/
4. 消息队列
这里时进程处理的最后一部分,我没有写文档,后面时线程和线程池,我之前学过,不再重新看,直接跳过到内核原理。
内核原理
进程控制块(PCB)
内核会保存每个进程的一些信息,称为进程控制块(Process Control Block, PCB), 内容:
- 进程编号(PID),每个进程对应的唯一编号,一般为正整数形式。
- 进程状态信息。
- 进程切换时需要保存和恢复的一些CPU寄存器,其中关键的有程序计数器的值,用于记录进程恢复时应执行的指令地址。
- 内存管理信息,如页表、内存限制、段表等。
- 当前工作目录。
- 进程调度信息,包括进程优先级、调度队列指针等。
- I/O状态信息,包括分配给进程的I/O设备列表,打开的文件描述符表等,后者包含很多指向file结构体的指针。
- 同步和通信信息,包括信号量、信号等用于进程同步和通信机制的信息。
- 用户id和组id。
进程的内存模型
内核空间
内核空间是进程虚拟内存中保留给操作系统内核的部分,用于存放内核代码和数据。这部分空间对用户程序是不可见、不可访问的。内核空间具有最高的访问权限,只有内核态下的代码可以执行这里的操作。所有进程的内核空间是共享的。
用户空间
用户空间是内存中分配给用户程序的部分,与内核空间相隔离。用户程序和库函数在这里执行。用户空间的代码运行在用户态,拥有较低的权限,不能直接执行特权操作或访问内核空间。
虚拟内存
虚拟内存是计算机系统内存管理的一种计数,它为每个进程提供了一种“虚拟”的地址空间,这个地址空间对于每个程序来说看起来都是连续的,但实际上可能被分散地存储在物理内存和磁盘上(如交换空间或页面文件)。虚拟内存允许系统超额分配内存,即分配的内存总量可以超过物理内存的实际容量。虚拟内存简化了内存的管理,使得应用程序不需要关心物理内存的实际情况。
MMU
虚拟地址到真实地址的桥梁。
中断和异常的区别
在X86-64架构中,中断和异常区别在于:中断处理历程被调用时,CPU会清楚EFLAGS寄存器中的IF(Interrupt Enable)位,避免其他中断干扰当前中断处理例程的执行。而异常处理历程被调用时IF不会被清除。
中断描述符表
操作系统为每种中断和异常都分配了唯一的中断向量(Vector),它是一个非负整数。一部分中断向量是由CPU的设计者分配的(如被零除、缺页、内存访问违例即算数运算溢出等),另一部分中断向量是由操作系统内核的设计者分配的(报错系统调用和来自外部I/O设备的信号)。
操作系统启动时,内核会分配和初始化一张称为中断描述符表的跳转表,将中断向量和中断或异常理出程序映射。IDT中的每一项对应一种中断或异常。
中断描述符表寄存器指明了IDT的基地地址和边界。
fork()底层原理
- 为子进程创建内核栈、thread_info 实例。
- 复制父进程的task_struct,后者包含了内核栈、虚拟内存管理信息、打开的文件描述符表等的指针,此时子进程只是复制了这些资源的引用。
- 清楚子进程的统计信息,更新子进程task_struct 的标志位。
- 为子进程分配新的PID,将子进程的PPID设置为调用fork()的进程。
- 清除与fork()返回值相关的寄存器,使得子进程中fork()返回的是0。
- 复制打开的文件描述符表,这一过程底层被指向的struct file实例中引用计数加一。复制文件系统信息、复制地址空间(页表相关信息),复制信号处理信息。
- 最后,如果子进程成功创建则被唤醒,处于就绪态。
execve()底层原理
- 参数和环境准备内核检车传递给execve()的参数,包括可执行文件的路径、环境变量和命令行参数,以确保他们的有效性和安全性。这个阶段内核会在内核空间中准备一份新程序需要的命令行参数和环境变量的备份。
- 打开和验证可执行文件打开指定的二进制文件,验证其格式是否支持(例如,ELF格式),并检查执行权限。如果这一步找不到可执行文件的路径,就会直接终止。
- 创建新的内存映射。清除进程当前的内存映射,包括用户空间中的代码、数据、堆和栈。根据新的程序建立新的代码段、数据段、堆和栈等。需要注意的是,内存映射不包含内核空间,内核空间的映射是由操作系统内核管理的,对所有进程是共享的。execve切换的只是用户空间。
- 复制参数和环境变量。在新的地址空间中为命令行参数和环境变量分配空间,并将内核中他们的备份复制到新的位置。
- 初始化进程上下文设置新的程序计数器、栈指针等,以便新程序可以正确执行。清理和重设进程的各种内核资源,如文件描述符表。根据文件描述符的close-on-exec标志(FD_CLOEXEC)进行处理,如果由该标志,则文件描述符被关闭。
- 更新task_struct 和其他内核结构更新task_struct中关于进程地址空间、堆栈、命令行参数、环境变量的指针。重置信号控制信息到默认状态。清理进程的各种内核状态,如未处理的信号、定时器等。
- 执行新程序跳转到新加载程序的入口点开始执行。
setpgid():允许手动调用setpgid给每一个进程设置自定义的组id
进程切换过程 — CPU
进程切换
主要在以下几种情况下发生:
- 时钟中断触发,被中断的进程获得的CPU时间片耗尽,操作系统决定切换进程。
- 当前进程发生故障,内核夺回CPU控制权,如果故障无法被修复,则内核终止该进程,切换至其他进程。
- 时钟中断触发,当前进程在等待IO操作,为避免资源浪费,切换至其他进程。
- 时钟中断触发,高优先级进程处于就绪状态,内核将CPU使用权由当前进程转交给高优先级进程。
进程上下文
进程上文是指进程被挂起时其执行状态的集合,这使得进程能够在未来某个时间点继续执行。它包括进程的程序计数器、栈指针等寄存器状态,进程的内核栈和用户栈的信息、内存映射信息(如页表头目),打开的文件描述符表等。
进程下文是指将要被加载和执行的挂起进程的执行状态集合。包括将要被执行的进程的程序计数器、栈指针等寄存器状态,进程的内核栈和用户栈的信息、内存映射信息(如页表条目),打开的我呢见描述符表等。
内核态
内核态是CPU的一种运行模式,具有执行所有指令和访问所有硬件资源的权限。在这种模式下,操作系统内核执行其核心功能。所有与硬件交互的操作都必须在内核态下执行。
由于具有完全的系统控制权,任何在内核态执行的代码都必须是高度可靠的,以避免系统崩溃或安全漏洞。
用户态
用户态是CPU的另一种运行模式,权限受限。应用程序在用户态下运行,不能直接执行特权指令或访问受保护的内存区域。
用户态为应用程序提供了一个安全的执行环境,通过系统调用请求操作系统提供的服务。
进程创建和线程创建的区别
从clone()系统调用的角度,我们可以得出结论:如果多个进程共享了地址空间、文件系统信息、打开的文件信息、信号处理信息,那么他们就是同属于一个进程的线程。
task_struct结构体中的pid实际上表示的是进程或线程ID,tgid字段表示的是线程组ID,等同于传统意义上的线程ID。对于单线程的进程,pid字段和tgid字段相同。对于多线程进程,主线程的pid等于tgid,pid此时可以理解为主线程的线程ID或者进程ID,普通线程的tgid等于主线程的pid和tgid,即当前线程所属的线程组ID和进程ID,而pid字段此时相当于线程ID。
线程的特点
- 资源共享:线程之间共享进程资源,包括地址空间、文件系统信息、打开的文件描述符和信号处理函数,而不同进程之间的资源是隔离的。
- 通信:线程间的通信通常比进程间的通信更为高效,因为地址空间是共享的,线程间可以直接用过如全局变量这样的方式通信。
- 创建和管理开销:线程的创建和上下文切换通常比进程更轻量级,因此在需要频繁创建和销毁执行单元的场景中,线程可能是更合适的选择。
Socket编程
计算机网络分层
分层、实体、协议、接口、服务
TCP传输协议定义了如何在网络种的两个点之间可靠地传输数据。
接口是网络分层模型种,定义相邻两层之间如何交互的规范。它对定了一层如何向另一层提出服务请求,以及这些请求怎样被另一层接收和相应。接口包含了一系列的规则、命令、数据格式和过程,确保不同网络层之间的有效通信和数据交换。
服务访问点(SAP)是接口概念的一个组成部分,具体化了接口在实现层次服务中的作用。接口定义了相邻层之间交互的规范和方式,而SAP则是这种交互发生的具体逻辑位置。换句话说,SAP为接口提供了一个具体的实施机制,使得上层能够访问下层提供的服务。
服务是指下层为紧邻上层提供的功能调用,是垂直方向的。描述了上层可以利用的具体功能和操作,但不涉及这些功能是如何实现的。服务强调的是功能性的提供,而不是实现细节。服务描述了“做什么”(功能),而不是“如何做”(实现细节)。服务是抽象的,隐藏了下层如何完成这些任务的具体细节,使得上层可以不依赖于下层的具体实现来进行设计和开发。
上层是通过SAP来访问下层服务的。
OSI七层模型
自下而上:物理层、数据链路层、网络层、传输层、会话层、表示层、应用层
物理层:负责传输原始比特流。它涉及的是物理设备及介质,如电缆类型、电信号传输和接收等。
数据链路层:确保物理链路上的无误传输。它提供了如帧同步、流量控制和错误检测等功能。
网络层:负责数据包从源到目的地的传输和路由选择。它定义了地址的路由和概念,如IP协议。
传输层:提供端到端的数据传输服务,保证数据的完整性。它定义了如TCP和UDP协议。
会话层:管理会话,控制建立、维护和终止会话。
表示层:处理数据的表示、编码和解码,如加密和解码。
应用层:提供网络服务给终端用户的应用程序,如HTTP、FTP、SMTP等协议。
TCP/IP四层模型
TCP/IP四层模型,亦称互联网协议套件,是一种按照功能标准组织互联网及类似计算机网络中使用的一系列通信协议的框架。该套件中的基础协议包括传输控制协议(TCP)、用户数据报协议(UDP)和互联网协议(IP)。
TCP/IP协议栈是指TCP/IP协议套件的软件实现。
1. 应用层
这层是用户最直接交互的部分,是软件应用通过网络进行通信的地方。应用层使用下层提供的服务来创建用户数据,将这些数据传输给同一台机器上或远程机器上的其他应用。
协议:该层包括了SMTP、FTP、SSH、HTTP等协议,这些协议都在应用层上实现,以实现客户端与服务器之间的通信和数据交换。
2. 传输层
传输层管理着端到端的通信,即主机到主机的通信。它的主要职责是为不同主机上的应用程序提供数据传输,同时保证这些数据的完整性和可靠性。
协议:在传输层,主要的协议有TCP,它提供顺序的、可靠的、双向的连接流,并管理报文段的发送,确保无错误、不丢失、不重复、按序到达;以及UDP,它提供一种无连接的服务,数据以数据报的形式发送,不保证顺序或相应。
3. 互联网层
互联网层处理跨网络界限的数据包交换,负责将数据报文段从源地址路由到目的地址。这层抽象了实际的物理网络拓补结构,并且定义了如何在各种网络结构中发送和接收数据包。
网络层的IP协议是构成Internet的基础。Internet上的主机都是通过IP地址来相互识别。IP协议不保证传输数据的可靠性,可能出现丢包等情况。
协议:主要协议是IP,它定义了数据包的路由方式和网络地址。其他重要的协议包括ICMP,用于错误报告和网络诊断。
4. 链路层
链路层涉及到在物理网络上的数据通信。链路层确保网络层传来的IP数据报可以在网络的物理链接上进行传输,不管是通过有线还是无线媒介。它负责处理与物理网络链接相关的问题,例如MAC地址寻址、帧同步、错误检测和校正。
协议:它包括了在物理网络链接中使用的所有协议,如以太网、WI-FI以及PPP。
网络传输中的数据单元
PDU
协议数据单元,计算机网络各层对等实体间交换信息的数据单元。PDU包括头部(PCI)和负载(SDU)。不同层次的PDU有专门的术语,例如在网络层,PDU称为数据包,在传输层,PDU称为报文段或数据报,在数据链路层,PDU称为帧。
数据包:通常指网络层(如IP网络层)的数据单位。
报文段:通常用于描述传输层(TCP传输层)的数据单位。
数据报:通常用于描述UDP协议的数据单位,它也是传输层的一个概念。
SDU
服务数据单元是在通信协议的特定层次上传递的数据单元。这些数据被传递给下一层,由下一层进行处理或封装,并附加控制信息(PCI),将其转换为那一层的PDU。SDU是用户数据或者来自上一层的PDU,未包括当前层可能添加的头部或其他控制信息。
PCI
协议控制信息是PDU中的元数据部分,它包括用于在网络中传输数据的控制信息,比如地址、端口号、控制标志、协议类型等。它与SDU一起被封装成PDU。PCI基本上是头部和尾部信息,它使得网络或传输实体能够理解如何处理包含的SDU。
PDU = SDU+PCI
传输层-TCP协议
TCP(传输控制协议)是一种面向连接的、可靠的、基础字节流的传输层通信协议,广泛应用于互联网中。它旨在提供可靠的端到端通信,在发送数据之前,需要在两个通信断电之间建立连接。TCP通过一系列机制确保数据的可靠传输,这些机制包括序列号、确认应答、重传控制、流量控制和拥塞控制。
TCP协议的特征
- 面向连接TCP是一种面向连接的协议,这意味着在数据交换之前,两个通信端必须先建立连接。这个连接通过一个三次握手过程来建立,确保双方都准备好数据交换。
- 可靠传输TCP通过序列号和确认应答机制确保数据的可靠传输。发送方为每个报文段分配一个序列号,接收方通过发送确认应答来确认已经收到特定序列号的报文段。如果发送方没有在合理的超时时间内收到确认应答,它将重传该报文段。
- 流量控制TCP使用窗口大小调整机制来进行流量控制,防止发送方过快地发送数据,导致接收方来不及处理。通过调整窗口大小,TCP能够动态地管理数据的传输速率,避免网络拥堵和数据丢失。
- 拥塞控制TCP实现了拥塞控制算法(如慢启动、拥塞避免、快重传和快恢复),以避免网络中的过度拥塞。这些算法可以根据网络条件动态调整数据的发送速率,从而提高整个网络的效率和公平性。
- 数据排列由于网络延迟和路由变化,TCP报文段可能会乱序到达接收方。TCP能够根据序列号重新排序连续到达的报文段,确保数据以正确的顺序交付给应用层。
- 端到端通信、TCP提供端到端的通信。每个TCP连接由四个关键元素唯一确定:源IP地址、源端口号、目标IP地址、目标端口号。这种方式确保了数据能够在复杂的网络环境中准确地从一个断电传输到另一个端点。
- URG:紧急标志,为1表示当前报文段存在被发送端上层实体置为“紧急”地数据。接收方应当优先处理这些数据。紧急指针字段指出了这部分数据地结束位置。
- ACK:确认标志,为1指示确认字段的值是有效的。该报文段包含对己被成功接收报文段的确认。连接建立后,直至释放前传输的所有报文段ACK标志均为1。
- PSH:为1指示接收方应立即将数据上交给上层。
- RST:为1表示链路出现错误,要求接收方终止连接,并重新建立连接。
- SYN:该标志位用于建立连接。TCP连接建立时的前两次握手SYN为1。
- FIN:为1表示发送方已经没有数据发送,想要断开连接。
TCP连接的建立和释放
TCP连接的三次握手
TCP连接建立过程又称三次握手
- 第一次握手:Client -> Server
- 动作: 客户端发送一个 SYN (Synchronize) 报文包,并随机生成一个初始序列号 seq = x。
- 状态: 客户端进入
SYN_SENT状态。 - 意义: 告诉服务器:“我想建立连接。”
- 第二次握手:Server -> Client
- 动作: 服务器收到 SYN 包后,需要确认客户端的请求。它会发送一个 SYN + ACK 报文包。
- 确认号 ack = x + 1(表示收到了客户端的 x)。
- 同时也发送自己的初始序列号 seq = y。
- 状态: 服务器进入
SYN_RCVD状态。 - 意义: 告诉客户端:“收到了,我也准备好了,你确认一下?”
- 第三次握手:Client -> Server
- 动作: 客户端收到服务器的包后,发送一个 ACK (Acknowledgment) 报文包。
- 确认号 ack = y + 1。
- 序列号 seq = x + 1。
- 状态: 双方进入
ESTABLISHED状态,连接成功。 - 意义: 告诉服务器:“收到确认,我们开始传输数据吧!”
为什么要三次?两次不行吗?
答:两次握手无法防止失效的连接请求突然传送到服务器,从而导致资源浪费。
- 第一次握手:Server确认了“对方发送正常,自己接收正常
- 第二次握手:Client确认了”对方发送、接收正常、自己发送、接收也正常“
- 第三次握手:Server确认了”对方接收正常,自己发送正常“
TCP连接的四次挥手
- 第一次挥手:Client -> Server
- 动作: 客户端发送一个 FIN (Finish) 报文,用来关闭客户端到服务器的数据传送。
- 状态: 客户端进入
FIN_WAIT_1状态。 - 意义: “我这边没数据要发了,我想关掉连接。”
- 第二次挥手:Server -> Client
- 动作: 服务器收到 FIN 后,发送一个 ACK 报文。
- 状态: 服务器进入
CLOSE_WAIT状态,客户端收到后进入FIN_WAIT_2。 - 意义: “收到你的申请了,但我可能还有点数据没传完,你等我一下。”
- 注意: 此时处于半关闭状态,客户端不能发数据,但能接收服务器发来的剩余数据。
- 第三次挥手:Server -> Client
- 动作: 服务器处理完所有剩余数据后,向客户端发送一个 FIN 报文。
- 状态: 服务器进入
LAST_ACK状态。 - 意义: “我也传完了,可以正式关掉了。”
- 第四次挥手:Client -> Server
- 动作: 客户端收到 FIN 后,发回一个 ACK 确认。
- 状态: 客户端进入
TIME_WAIT状态,等待 2MSL 后关闭;服务器收到 ACK 后直接进入CLOSED。 - 意义: “收到,再见!”
为什么需要TIME_WAIT(2MSL)?
答:客户端在发送完最后一个 ACK 后,并不会立即关闭,而是要等待 2MSL (Maximum Segment Lifetime,报文最大生存时间)。主要有两个原因:
- 保证最后一个ACK能够到达服务器:如果这个ACK丢了,服务器会超时重发第三次的FIN。如果客户端直接关了,服务器九永远等不到回应,无法正常关闭。
- 防止”已失效的请求“:确保本次连接中产生的所有报文都在网络中消失,以免影像下一个新的连接。
总结:为什么建立是三次,关闭是四次?
- 建立连接时: 当服务器收到 SYN 后,可以同时把 ACK(确认)和 SYN(同步)放在一个包里发过去。
- 关闭连接时: 当服务器收到 FIN 时,它可能还有数据要处理。所以它先回一个 ACK 告诉客户端“收到了”,等自己也准备好了,再发第二个 FIN 包。ACK 和 FIN 往往不能合并发送,因此多了一次。
可靠传输保障
累计确认
TCP的累计确认是指接收方发送的ACK报文中的确认号表示的是接收方期望接收的下一个字节的序列号。这意味着所有比这个确认号小的字节已经被成功接收。
延时确认
接收方在接收到每个报文段后,不会立即发送确认报文(ACK),而是会等待一段时间,看是否有其他报文段到达或者接收方是否有数据要发送。这种情况下,接收方可以将多个确认合并为一个ACK报文。这种机制被称为延时确认,目的是减少ACK报文的数量,从而降低网络开销。
超时重传
当发送方发送数据后,如果在预定时间内未收到接收方的确认(ACK),发送方会假设该数据段丢失,并重新发送该数据段,
滑动窗口
在TCP通信中,双方各自维护一个缓冲区。当发送速率大于接收速率时,接收方的缓冲区可能会被填满。如果发送方继续发送数据,后面的数据只能被丢弃,造成资源浪费,为了避免这种情况,TCP提供了滑动窗口机制来控制发送方的发送速率。
TCP报文段的头部有一个字段时窗口大小,这里的窗口是指接收窗口
。接收方可以在返回的ACL报文段中通过窗口大小字段告诉我接收方当前可用的缓冲区即接收窗口大小。接收窗口大小随数据传输动态变化,当窗口大小变化为0时,发送方会暂停数据发送。一段时间后,接收方腾出了足够的空间来接收数据,他会发送报文段通知发送方继续发送。
拥塞控制
拥塞控制是保网络在面对海量数据传输时,不会因负载过重而陷入“瘫痪”的关键技术。拥塞控制的目标就是让发送方动态调整发送速率,在充分利用带宽的同时,避免网络崩溃。
- 慢启动(Slow Start):初始 cwnd 很小(通常为 1-10 个 MSS)。每收到一个确认报文(ACK),cwnd 翻倍。
- 拥塞避免(Congestion Avoidance):当 cwnd 达到慢开始门限 (ssthresh) 时,每一轮往返时间(RTT)将 cwnd 增加 1。
- 快重传(Fast Retransmit):如果接收方收到一个失序的报文段,就立即发出重复确认。当发送方连续收到 3 个重复确认 时,认为数据包已丢失,立即重传,而不必等待超时计时器到期。
- 快恢复(Fast Recovery):在“快重传”之后,发送方认为网络虽然拥塞但还没瘫痪(因为还能收到重复 ACK)。此时不执行慢开始,而是将 ssthresh 减半,并将 cwnd 设置为减半后的值,直接进入拥塞避免阶段。
为什么拥塞控制非常重要?
如果没有拥塞控制,当网络出现拥堵时,路由器会丢弃数据包。发送方因为收不到确认,会认为丢包并不断重传,这回进一步加剧网络拥堵,形成拥塞崩溃,拥塞控制让互联网在面临突发流量时具备了强大的弹性。
发送窗口
发送窗口是发送方在等待接收方确认(ACK)之前,能够发送的数据量的最大上限。
发送窗口的大小并不是固定的,它收到接收窗口和拥塞窗口两个因素的共同制约,他是接收窗口和拥塞窗口的最小值。
TCP开发常见函数
socket 套接字
套接字是计算机网络数据通信的基本概念和编程接口,允许不同主机上的进程通过网络进行数据交换,他为应用软件提供了发送和接收数据的能力,使得开发者可以在不用深入了解底层网络细节的情况下进行网络编程。
一个套接字主要有三个属性组成
- 网络地址:通常是IP地址,用于标识网络上的设备。
- 端口号:用于标识设备上的特定应用或进程。端口号是一个16位的数字,范围从0-65535.
- 协议:如TCP(传输控制协议)或UDP(用户数据报协议),定义了数据传输的规则和格式。
套接字的工作原理:套接字通过封装TCP/IP协议细节,提供了一组API,允许应用程序创建套接字、绑定地址和端口、监听连接、接收连接、发送和接收数据等。在网络通信中,通常一个套接字负责监听和接收外部连接(服务器套接字),另一个套接字负责发起连接(客户端套接字)。
Socket 的主要类型
根据传输层协议的不同,Socket 主要分为以下两类:
- 流式套接字 (Stream Socket / TCP):
- 面向连接,提供可靠、无差错、无重复且按序到达的数据传输。
- 就像打电话,必须先建立通话连接。
- 数据报套接字 (Datagram Socket / UDP):
- 无连接,不保证可靠性,但速度快。
- 就像寄明信片,发出去就不管了,对方不一定收到。
Socket 通信的基本流程
对于最常见的 TCP Socket,通信过程遵循典型的客户端-服务端模型:
服务端 (Server)
- socket(): 创建一个套接字。
- bind(): 将套接字绑定到特定的 IP 地址和端口上。
- listen(): 进入监听状态,等待客户端连接。
- accept(): 接受客户端连接(此步会阻塞,直到有连接进来)。
- read/write: 进行数据交换。
客户端 (Client)
- socket(): 创建一个套接字。
- connect(): 尝试与服务端的 IP 和端口建立连接(触发 TCP 三次握手)。
- write/read: 进行数据交换。
字节序
大端序:数据的高位字节存放在内存的低地址端,低位字节存放在高地址处,这种字节序被称为网络字节序,在网络协议(TCP/IP)中必须使用大端序进行传输。
小端序:数据的低位字节存放在内存的低地址端,高位字节存放在高地址处,这是Intel x86-64架构以及其他一些现代处理器普遍采用的字节序,称为主机字节序。
IP协议
IP是网络通信中最基础的协议之一,用于在不同的网络设别之间传输数据。IP协议定义了数据包的格式和寻址方法,使得数据能够从源地址传输到目标地址。
IP地址是分配给连接到计算机网络的每个设备的唯一标识符,用于在网络中进行通信,IP地址使数据包在网络上能够找到其目标位置,确保数据从源设备传输到目标设备。
DNS域名解析协议
域名是互联网上用于标识网站的易于记忆的名称,代替了难记的IP地址,使用户能够方便地访问网站。域名由一些列标签组成,这些标签由点(.)分隔,每个标签代表域名层次结构中的一个级别。
DNS协议是一种用于将人类易读的域名转换为计算机可以识别的IP地址的网络协议。它是互联网的关键组件之一,使用户能够使用友好的域名而不是难记的IP地址来访问网站和其他互联网资源。
守护进程
守护进程是在操作系统后台运行的一种特殊类型的进程,它独立于前台用户界面,不与任何终端设备直接关联。这些进程通常在系统启动时启动,并持续运行直到系统关闭,或者他们完成其任务并自行终止。守护进程通常用于服务请求、管理系统或执行周期性任务。它们的名字通常以字母d结尾(如httpd, sshd, mysqld)
编程规则
- 创建子进程并结束父进程在UNIX和类UNIX系统中,进程是通过复制(使用fork())创建的,守护进程需要在后台独立运行。
- setsid() 设置会话IDsetsid()创建一个新会话,并使调用它的进程称为新会话的领导者,这样做的主要目的是让守护进程摆脱原来的控制终端。这样,守护进程就不会接收到终端发出的任何信号,例如挂断信号(SIGHUP),从而保证其运行不受前台用户操作的影响。
- 第二次fork()使得守护进程不是会话领导,没有获取控制终端的能力,避免意外获取控制终端。
- chdir(“/”) 更改工作目录将工作目录更改到跟目录(/),主要是为了避免守护进程继续占用其启动时的文件系统。这对于可移动的或网络挂载的文件系统尤为重要,确保这些文件系统不需要时可以被卸载。
- umask(0) 重设文件权限掩码调用umask(0)确保守护进程创建的文件权限不受继承的umask值的影响,守护进程可以更精确地控制其创建地文件和目录的权限。
- 关闭文件描述符守护进程通常不需要便准输入、输出和错误文件描述符,因为它们不与终端交互。关闭这些不需要的文件描述符可以避免资源泄露,提高守护进程的安全性和效率。
- 处理信号SIGHUP和SIGTERM信号SIGHUP: 虽然守护进程和终端断开,但仍然有可能收到其他进程或内核发来的SIGHUP信号,守护进程不应该因为它而终止。SIGTERM: SIGTERM信号时终止信号,用于请求守护进程优雅地终止。通过命令行执行kill< pid >命令可以发送SIGTERM信号,接收到这个信号之后,守护进程终止子进程,并清理回收资源,最后退出。
- 执行具体任务这一步是守护进程的核心,他开始执行为其设计的特定功能,如监听网络请求、定期清理文件系统、执行系统备份等。
现代Linux的管理方式: systemd
在Linux基础的开机自启动里详细记录,这里不再展开。
IO多路复用
IO多路复用是高性能网络编程的核心,它允许一个进程(或线程同时监听多个文件描述符(FD),只要其中任何一个就绪,内核就会通知进程。
select
- 机制:进程把要监听的 FD 集合拷贝给内核,内核线性扫描所有 FD,有数据了标记一下,再拷回给进程。
- 缺点:
- 数量限制:通常限制只能监听 1024 个 FD(由
FD_SETSIZE定义)。 - 开销大:每次都要在用户态和内核态之间拷贝整个集合。
- 效率低:进程拿到返回后,还得自己 O(n) 遍历一遍才知道是谁就绪了。
- 数量限制:通常限制只能监听 1024 个 FD(由
poll
- 机制:和 select 类似,但改用了链表存储 FD。
- 改进:打破了 1024 个数量限制。
- 缺点:依然需要 O(n) 遍历和内核/用户态拷贝,高并发下性能依然线性下降。
epoll
- 机制:
- 事件驱动:不再是轮询,而是给每个 FD 注册回调函数。当 FD 就绪时,自动把该 FD 放入一个“就绪链表”。
- mmap:利用内核与用户空间共享内存,避免了频繁的数据拷贝。
- 优势:
- O(1) 复杂度:进程被唤醒后直接处理就绪链表,不需要遍历所有 FD。
- 支持巨量连接:监听 100 万个连接和监听 10 个连接效率几乎一致。
epoll的两种触发模式
- 水平触发 (LT, Level Triggered) – 默认: 只要缓冲区里有数据,内核就会一直通知你。没处理完?下次还通知你。比较保险。
- 边缘触发 (ET, Edge Triggered): 只有数据从无到有、或者增加时才通知一次。如果你没一次性读完,内核就不再通知了。
- 优点:减少了 epoll 事件触发次数,效率更高。
- 要求:必须配合非阻塞 IO,且循环读取直到返回
EAGAIN。









