
说明:这是我对开发板上没有部署例程的模型,进行的一次部署尝试,后续会以此为基础测试更多RDKS100P上没有demo的模型。
Github:NieQuan-kzzx/deeplabv3plus_Deploy_to_RDKS100P: 这里记录了一次deeplabv3+模型部署到RDKS100P的示例,详细的模型部署流程可以查看我的个人博客。
内容:
转化:pytorch训练的浮点型模型转板端bpu推理的int8的hbm模型,中间格式onnx。
部署:板端部署,使用转化后的hbm模型
工具链:OE,天工开物
统一计算平台(UCP)
模型部署流程流程:
- 得到模型的onnx文件
- 借助OE工具链,将其转化为BPU推理使用的hbm文件
- 根据模板和文档,使用模型推理
以deeplabv3+为例,记录一次模型部署流程。
- hb_compile: 将onnx格式模型转化为hbm模型
- 检查onnx模型中有那些算子是BPU不支持的
- 删除特定的节点名称
- 参考官方给的例程转化的验证集,npy格式数据配置文件,特别提醒,如果要用自己训练的模型,验证集的图片大小最好与模型的输入大小一致
- 参考官方给出的例子进行修改转化之后会得到一些日志文件和输出的html文件可以查看模型的静态特性
- 动态精度:hrt_model_exec perf –model_file model.hbm
- hb_model_info:解析hbm和bc编译时的依赖及参数信息、onnx模型基本信息,同时支持对bc可删除节点进行查询
- hb_model_info ${model_file}
- 重点关注输入和输出
- input_y input [1, 224, 224, 1] UINT8
- input_uv input [1, 112, 112, 2] UINT8
- output output [1, 1000]
- FLOAT32deeplabv3+的输出信息为:
- 2026-01-19 16:22:17,965 INFO input.1_y input [1, 1024, 2048, 1] UINT8
- 2026-01-19 16:22:17,966 INFO input.1_uv input [1, 512, 1024, 2] UINT8
- 2026-01-19 16:22:17,966 INFO 705 output [1, 1, 1024, 2048] INT8
- 根据官方的其他模型推理案例的源码来进行测试和修改,主要在于数据的对齐很难搞,输出格式不对不能输出正确的结果。板端部署:统一计算平台(这个是OE工具链里带的,这个工具链的docker镜像是部署在开发机的wsl ubuntu环境)官方示例:RGB输入的ResNet18模型部署
其他PTQ转化工具:
- hb_verifier: 一致性验证工具,两模型之间的余弦相似度对比、输出一致性对比、余弦相似度越接近1,说明对比的两个量化模型的输出越接近。一致性对比会打印对比模型的输出一致性信息,包括输出名称、一致性、不一致元素数量、最大绝对误差、最大相对误差
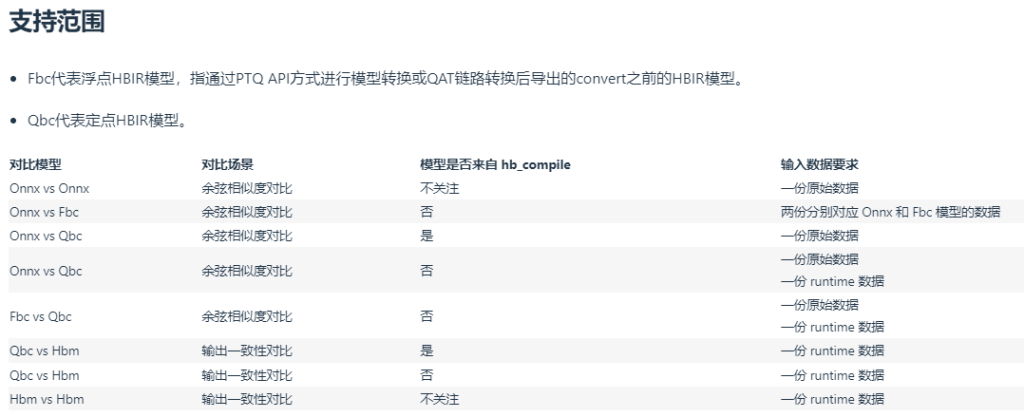
- hb_eval_preprocess: 用于对模型精度进行评估时,在x86环境下对图片数据进行预处理。
- hb_config_generator: 用于支持您获取模型编译最简yaml配置文件、包含全部参数默认值的yaml配置文件的工具。
- hb_config_generator –simple-yaml:生成嘴贱yaml配置文件
- hb_config_generator –simple-yaml –model model.onnx –march nash-e:生成基于模型信息的最简yaml配置文件
- hb_config_generator –full-yaml:包含全部参数默认值的yaml配置文件
- hb_config_generator –full-yaml –model model.onnx –march nash-e:生成基于模型信息的全部参数默认值yaml配置文件
HBRuntime推理库:地平线提供的一套x86端模型推理库,支持对常用训练框架直接导出的onnx原始模型、地平线工具链进行PTQ转化过程中产出的各阶段onnx模型以及地平线工具链转化过程中产出的bc模型和hbm模型进行推理
import numpy as np
# 加载地平线依赖库
from horizon_tc_ui.hb_runtime import HBRuntime
# 准备模型运行的输入,此处`input.npy`为处理好的数据
data = np.load("input.npy")
# 加载模型文件,根据实际模型进行设置
# ONNX模型
sess = HBRuntime("model.onnx")
# HBIR模型
sess = HBRuntime("model.bc")
# HBM模型
sess = HBRuntime("model.hbm")
# 获取输入&输出节点名称
input_names = sess.input_names
output_names = sess.output_names
# 准备输入数据,根据实际输入类型和layout进行准备,配置格式要求为字典形式,输入名称和输入数据组成键值对
# 如模型仅有一个输入
input_feed = {input_names[0]: data}
# 如模型有多个输入
input_feed = {input_names[0]: data1, input_names[1]: data2}
# 进行模型推理,推理的返回值是一个list,依次与output_names指定名称一一对应
output = sess.run(output_names, input_feed)
ONNX模型推理:
import numpy as np
# 加载地平线依赖库
from horizon_tc_ui.hb_runtime import HBRuntime
# 准备模型运行的输入,此处`input.npy`为处理好的数据
data = np.load("input.npy")
# 加载模型文件
sess = HBRuntime("model.onnx")
# 获取模型输入节点信息
input_names = sess.input_names
# 假设此模型只有一个输入,开始模型推理
output = sess.run(None, {input_names[0]: data})
HBIR(.bc)模型推理
import numpy as np
# 加载地平线依赖库
from horizon_tc_ui.hb_runtime import HBRuntime
# 准备模型运行的输入,此处`input.npy`为处理好的数据
data = np.load("input.npy")
# 加载模型文件
sess = HBRuntime("model.bc")
# 获取模型输入节点信息
input_names = sess.input_names
# 假设此模型只有一个输入,开始模型推理
output = sess.run(None, {input_names[0]: data})
HBM模型推理
import numpy as np
# 加载地平线依赖库
from horizon_tc_ui.hb_runtime import HBRuntime
# 准备模型运行的输入,此处`input.npy`为处理好的数据
data = np.load("input.npy")
# 加载模型文件
sess = HBRuntime("model.hbm")
# 获取模型输入节点信息
input_names = sess.input_names
# 假设此模型只有一个输入,开始模型推理
output = sess.run(None, {input_names[0]: data})
Debug工具:暂时还没有仔细研究,列为TODO
示例:
- deeplabv3+模型部署
#include <iostream>
#include <vector>
#include <cstring>
#include <opencv2/opencv.hpp>
#include "hobot/dnn/hb_dnn.h"
#include "hobot/hb_ucp.h"
#include "hobot/hb_ucp_sys.h"
///////////////////////////////////// 保存与可视化 //////////////////////////////////////////
/**
* @brief 将分割掩码转化为彩色图像
* @param mask 预测结果 (单通道灰度,值为类别ID)
* @param width 图像宽度
* @param height 图像高度
* @param filename 保存的路径
*/
void save_segmentation_result(const std::vector<uint8_t>& mask, int width, int height, const std::string& filename) {
if (mask.empty()) return;
// 将 mask 向量转为 cv::Mat,将vector 数据映射为OpenCV的单通道矩阵(CV_8UC1)
cv::Mat mask_mat(height, width, CV_8UC1, (void*)mask.data());
// 存放最终彩色结果的矩阵
cv::Mat color_mat;
// 1. mask_mat * 15: 将较小的类别索引(如 0, 1, 2)放大,以便在伪彩色映射中产生明显的颜色区分
// 2. applyColorMap: 将灰度值映射为 COLORMAP_JET 调色板颜色(蓝-绿-红渐变)
cv::applyColorMap(mask_mat * 15, color_mat, cv::COLORMAP_JET);
// 将处理后的彩色图像写入文件
cv::imwrite(filename, color_mat);
std::cout << "Successfully saved segmentation result to " << filename << std::endl;
}
/**
* 将分割结果叠加到原图上
* @param src 原图 (BGR)
* @param mask 预测结果 (单通道灰度,值为类别ID)
* @param filename 保存的文件名
*/
void blend_segmentation(cv::Mat& src, const std::vector<uint8_t>& mask, const std::string& filename) {
int h = src.rows; // 矩阵行数,对应图像的高度
int w = src.cols; // 矩阵列数,对应图像的宽度
// 1. 将 mask 向量转为 cv::Mat
cv::Mat mask_mat(h, w, CV_8UC1, (void*)mask.data());
// 2. 将 ID 映射为彩色图 (使用 COLORMAP_JET)
cv::Mat color_mask;
cv::applyColorMap(mask_mat * 15, color_mask, cv::COLORMAP_JET);
// 3. 图像融合:dst = src * 0.6 + color_mask * 0.4 + 0
cv::Mat blended;
cv::addWeighted(src, 0.6, color_mask, 0.4, 0, blended);
// 4. 保存并显示
cv::imwrite(filename, blended);
std::cout << "Blended result saved to: " << filename << std::endl;
}
///////////////////////////////////// 数据处理 /////////////////////////////////////
/**
* @brief 准备分量分离的 NV12 输入数据
* @param image_path 本地图像路径
* @param inputs 输入张量数组(inputs[0]为Y,inputs[1]为UV)
* @return int 成功返回 0
*/
int prepare_nv12_input(const std::string& image_path, std::vector<hbDNNTensor>& inputs) {
if (inputs.size() < 2) return -1;
// 获取 Y 分量的尺寸
int h = inputs[0].properties.validShape.dimensionSize[1];
int w = inputs[0].properties.validShape.dimensionSize[2];
cv::Mat bgr = cv::imread(image_path);
if (bgr.empty()) return -1;
cv::Mat resized;
cv::resize(bgr, resized, cv::Size(w, h));
cv::Mat yuv420p;
cv::cvtColor(resized, yuv420p, cv::COLOR_BGR2YUV_I420);
// --- 填充 Input[0] (Y) ---
uint8_t* y_src = yuv420p.data;
uint8_t* y_dest = reinterpret_cast<uint8_t*>(inputs[0].sysMem.virAddr);
int y_stride = static_cast<int>(inputs[0].properties.stride[1]);
for (int i = 0; i < h; ++i) {
std::memcpy(y_dest + i * y_stride, y_src + i * w, w);
}
hbUCPMemFlush(&inputs[0].sysMem, HB_SYS_MEM_CACHE_CLEAN);
// --- 填充 Input[1] (UV) ---
uint8_t* u_src = yuv420p.data + (h * w);
uint8_t* v_src = u_src + (h * w / 4);
uint8_t* uv_dest = reinterpret_cast<uint8_t*>(inputs[1].sysMem.virAddr);
int uv_stride = static_cast<int>(inputs[1].properties.stride[1]);
for (int i = 0; i < h / 2; ++i) {
uint8_t* row_dest = uv_dest + i * uv_stride;
for (int j = 0; j < w / 2; ++j) {
row_dest[j * 2] = u_src[i * (w / 2) + j];
row_dest[j * 2 + 1] = v_src[i * (w / 2) + j];
}
}
hbUCPMemFlush(&inputs[1].sysMem, HB_SYS_MEM_CACHE_CLEAN);
return 0;
}
////////////////////////////////////// main函数 ///////////////////////////////////////
int main(int argc, char **argv) {
// hbDNNPackedHandle_t:指向打包的多个模型。
hbDNNPackedHandle_t packed_dnn_handle;
// 指定模型文件路径
const char* model_file_name = "/home/sunrise/Desktop/RDKS100_Drowning/tem/deeplabv3plus_efficientnetm2_1024x2048_nv12.hbm";
const char* image_file_name = "/home/sunrise/Desktop/test_deeplabv3+/test.png";
/*
从文件完成对dnnPackedHandle的创建和初始化。调用方法可以跨函数、跨线程使用返回的dnnPackedHandle
* hbDNNPackedHandle_t *dnnPackedHandle:指向多个模型
* char const **modelFileNames:模型文件路径
* int32_t modelFileCount:模型文件数量
* return:0 表示API成功
int32_t hbDNNInitializeFromFiles(hbDNNPackedHandle_t *dnnPackedHandle,
char const **modelFileNames,
int32_t modelFileCount);
*/
int ret = hbDNNInitializeFromFiles(&packed_dnn_handle, &model_file_name, 1);
if (ret != 0) return -1;
const char **model_name_list;
int model_count = 0;
/*
获取dnnPackedHandle中包含的模型名称列表和个数
* char const ***modelNameList:模型名称列表
* int32_t *modelNameCount:模型名称数量
* hbDNNPackedHandle_t dnnPackedHandle:指向多个模型
* return:0 表示API成功
int32_t hbDNNGetModelNameList(char const ***modelNameList,
int32_t *modelNameCount,
hbDNNPackedHandle_t dnnPackedHandle);
*/
hbDNNGetModelNameList(&model_name_list, &model_count, packed_dnn_handle);
// hbDNNHandle_t:指向单一模型
hbDNNHandle_t dnn_handle;
/*
从dnnPackedHandle所指向模型列表中获取一个模型的句柄,调用方可以跨函数、跨线程使用返回的dnnHandle
* hbDNNHandle_t *dnnHandle:指向一个模型
* hbDNNPackedHandle_t dnnPackedHandle:指向多个模型
* char const *modelName:模型名称
* return:0 表示API成功
int32_t hbDNNGetModelHandle(hbDNNHandle_t *dnnHandle,
hbDNNPackedHandle_t dnnPackedHandle,
char const *modelName);
*/
hbDNNGetModelHandle(&dnn_handle, packed_dnn_handle, model_name_list[0]);
int input_count = 0;
/*
获取dnnHandle所指向模型的输入tensor数量
* int32_t *inputCount:输入tensor数量
* hbDNNHandle_t dnnHandle:指向一个模型
* return:0 表示API成功
int32_t hbDNNGetInputCount(int32_t *inputCount,
hbDNNHandle_t dnnHandle);
*/
hbDNNGetInputCount(&input_count, dnn_handle);
// hbDNNTensor:输入tensor,用于存放输入输出的信息
std::vector<hbDNNTensor> input(input_count);
/*
获取dnnHandle所指向模型的输入tensor属性
* hbDNNTensorProperties *properties:输入tensor属性
* hbDNNHandle_t dnnHandle:指向一个模型
* int32_t inputIndex:输入tensor索引
* return:0 表示API成功
int32_t hbDNNGetInputTensorProperties(hbDNNTensorProperties *properties,
hbDNNHandle_t dnnHandle,
int32_t inputIndex);
*/
for (int i = 0; i < input_count; i++) {
hbDNNGetInputTensorProperties(&input[i].properties, dnn_handle, i);
auto &props = input[i].properties;
if (props.stride[0] < 0) {
// std::cout << "Fixing input[" << i << "] stride..." << std::endl;
if (i == 0) { // Y分量
// Input[0]: 1x1024x2048x1 (NV12)
props.stride[0] = 2097152;
props.stride[1] = 2048;
props.stride[2] = 1;
props.stride[3] = 1;
props.alignedByteSize = 2097152; // 1024 * 2048 * 1.5
} else if (i == 1) { // UV分量
// Input[1]: 1x512x1024x2 (NV12)
// 报错要求: stride[0] >= 1048576, stride[1] >= 2048
props.stride[0] = 1048576;
props.stride[1] = 2048;
props.stride[2] = 2; // 因为最后一个维度是 2
props.stride[3] = 1;
props.alignedByteSize = 1048576; // 512 * 2048
}
}
hbUCPMallocCached(&input[i].sysMem, props.alignedByteSize, 0);
}
prepare_nv12_input(image_file_name, input);
int output_count = 0;
/*
获取dnnHandle所指向模型的输出tensor数量
* int32_t *outputCount:输出tensor数量
* hbDNNHandle_t dnnHandle:指向一个模型
* return:0 表示API成功
int32_t hbDNNGetOutputCount(int32_t *outputCount,
hbDNNHandle_t dnnHandle);
*/
hbDNNGetOutputCount(&output_count, dnn_handle);
std::vector<hbDNNTensor> output(output_count);
/*
获取dnnHandle所指向模型的输出tensor属性
* hbDNNTensorProperties *properties:输出tensor的信息
* hbDNNHandle_t dnnHandle:指向一个模型
* int32_t outputIndex:输出tensor索引
* return:0 表示API成功
int32_t hbDNNGetOutputTensorProperties(hbDNNTensorProperties *properties,
hbDNNHandle_t dnnHandle,
int32_t outputIndex);
*/
for (int i = 0; i < output_count; i++){
hbDNNGetOutputTensorProperties(&output[i].properties, dnn_handle, i);
auto &props = output[i].properties;
if (props.stride[0] < 0) {
int64_t h = static_cast<int64_t>(props.validShape.dimensionSize[2]);
int64_t w = static_cast<int64_t>(props.validShape.dimensionSize[3]);
props.stride[0] = h * w;
props.stride[1] = h * w;
props.stride[2] = w;
props.stride[3] = 1;
props.alignedByteSize = static_cast<uint64_t>(h * w);
}
hbUCPMallocCached(&output[i].sysMem, props.alignedByteSize, 0);
}
hbUCPTaskHandle_t task_handle = nullptr;
ret = hbDNNInferV2(&task_handle, output.data(), input.data(), dnn_handle);
if (ret != 0 || task_handle == nullptr) return -1;
hbUCPSchedParam infer_sched_param;
HB_UCP_INITIALIZE_SCHED_PARAM(&infer_sched_param);
hbUCPSubmitTask(task_handle, &infer_sched_param);
hbUCPWaitTaskDone(task_handle, 0);
// 在循环外部先读取一次原图,用于叠加
cv::Mat original_img = cv::imread(image_file_name);
for (int i = 0; i < output_count; i++) {
hbUCPMemFlush(&(output[i].sysMem), HB_SYS_MEM_CACHE_INVALIDATE);
auto &props = output[i].properties;
int h = props.validShape.dimensionSize[2];
int w = props.validShape.dimensionSize[3];
int stride = static_cast<int>(props.stride[2]);
if (h <= 0 || w <= 0) continue;
int8_t *raw_ptr = reinterpret_cast<int8_t *>(output[i].sysMem.virAddr);
std::vector<uint8_t> seg_mask(static_cast<size_t>(h * w));
for (int row = 0; row < h; ++row) {
std::memcpy(seg_mask.data() + row * w, raw_ptr + row * stride, static_cast<size_t>(w));
}
// 保存纯色分割图
save_segmentation_result(seg_mask, w, h, "output_mask.png");
// 保存半透明叠加图
if (!original_img.empty()) {
cv::Mat resized_src;
cv::resize(original_img, resized_src, cv::Size(w, h)); // 确保原图尺寸与输出一致
blend_segmentation(resized_src, seg_mask, "output_blended.png");
}
}
// 释放资源
hbUCPReleaseTask(task_handle);
for (auto &in : input) hbUCPFree(&in.sysMem);
for (auto &out : output) hbUCPFree(&out.sysMem);
hbDNNRelease(packed_dnn_handle);
return 0;
}
cmake_minimum_required(VERSION 3.0)
project(deeplabv3+)
# 设置C++标准
set(CMAKE_CXX_STANDARD 11)
set(CMAKE_CXX_STANDARD_REQUIRED ON)
# 设置编译器标志
# libdnn.so depends on system software dynamic link library, use -Wl,-unresolved-symbols=ignore-in-shared-libs to shield during compilation
set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} -std=c++11 -Wl,-unresolved-symbols=ignore-in-shared-libs")
set(CMAKE_CXX_FLAGS_DEBUG " -Wall -Werror -g -O0 ")
set(CMAKE_C_FLAGS_DEBUG " -Wall -Werror -g -O0 ")
set(CMAKE_CXX_FLAGS_RELEASE " -Wall -Werror -O3 ")
set(CMAKE_C_FLAGS_RELEASE " -Wall -Werror -O3 ")
if (NOT CMAKE_BUILD_TYPE)
set(CMAKE_BUILD_TYPE Release)
endif ()
message(STATUS "Build type: ${CMAKE_BUILD_TYPE}")
# 设置OpenCV包
find_package(OpenCV REQUIRED)
# S100 UCP库路径配置
set(HOBOT_INCLUDE_PATH "/usr/include")
set(HOBOT_LIB_PATH "/usr/hobot/lib")
# 包含头文件路径
include_directories(${HOBOT_INCLUDE_PATH})
include_directories(${OpenCV_INCLUDE_DIRS})
# 链接库路径
link_directories(${HOBOT_LIB_PATH})
# 添加可执行文件
add_executable(main main.cc)
# 链接所需的库
target_link_libraries(main
${OpenCV_LIBS} # OpenCV库
dnn # S100 DNN推理库
hbucp # S100 UCP统一计算平台库
pthread # 多线程支持
rt # 实时库
dl # 动态链接库支持
m # 数学库
)
说明:
- 输入输出宏观:2026-01-19 16:22:17,965 INFO input.1_y input [1, 1024, 2048, 1] UINT8
2026-01-19 16:22:17,966 INFO input.1_uv input [1, 512, 1024, 2] UINT8
2026-01-19 16:22:17,966 INFO 705 output [1, 1, 1024, 2048] INT8 - Input[0] Y / Input[1] UV
运行结果
原图:

掩码图:
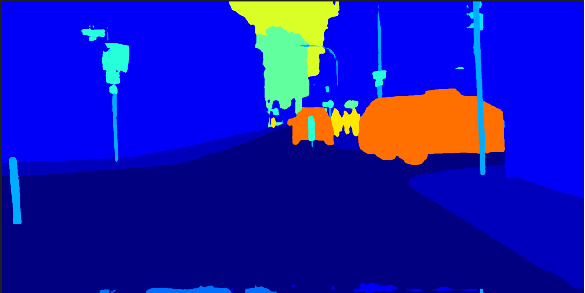
叠加到原图










